Publications
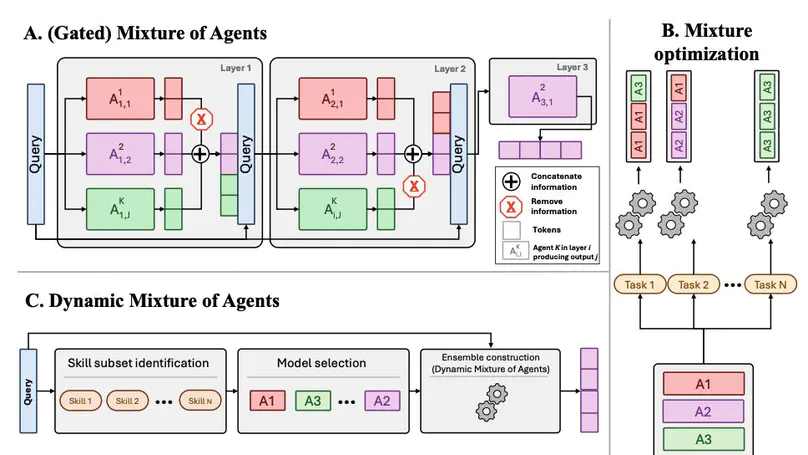
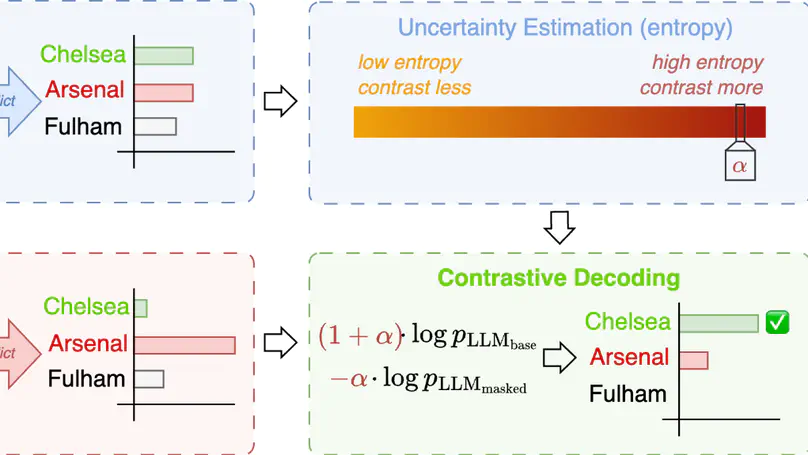

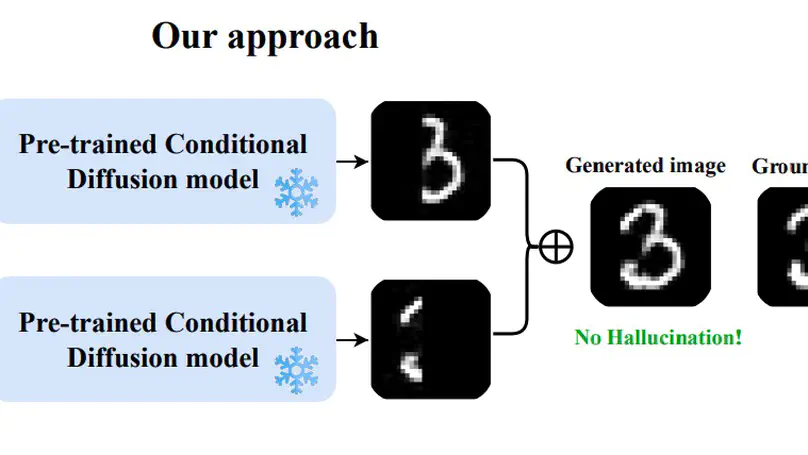


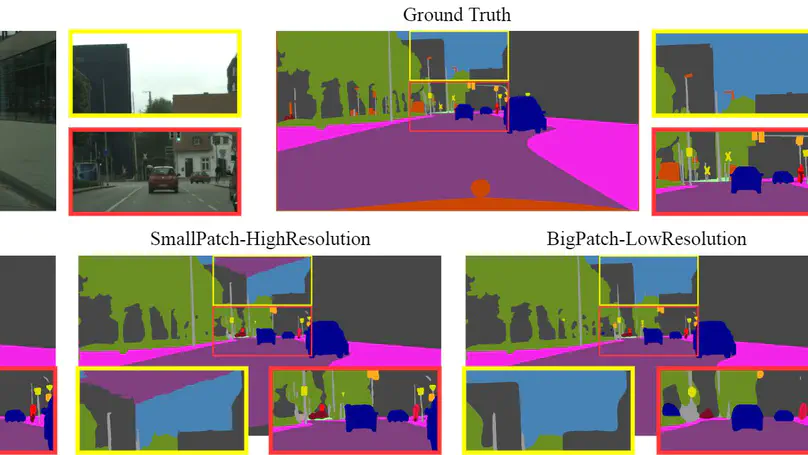
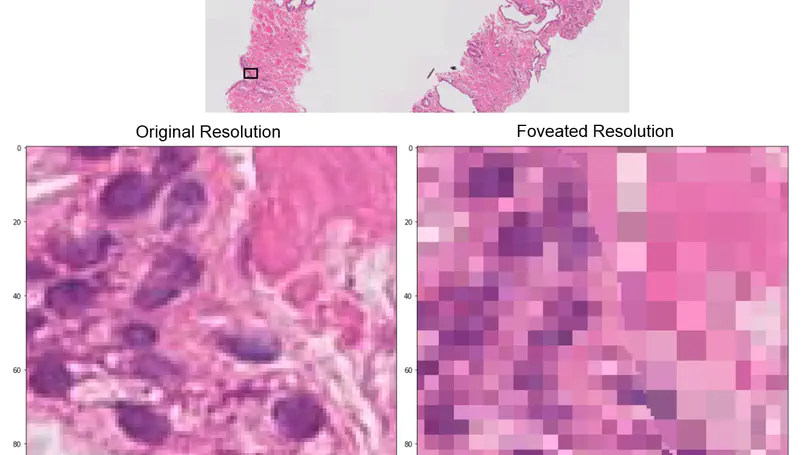
Building on our prior foveation work (MICCAI 2020), we introduce a more computationally efficient hard-gated categorical sampling method for FoV-resolution patch configurations with two differentiable solutions. We validate its generalizability on three vision datasets Cityscapes, DeepGlobe, and Gleason2019 histopathology.