Abstract
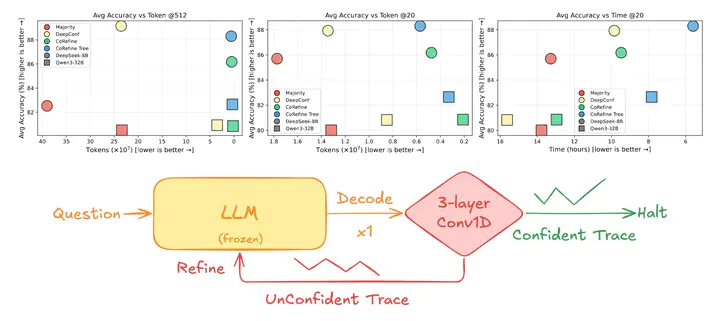
Large Language Models (LLMs) often rely on test-time scaling via parallel decoding (e.g., 512 samples) to boost reasoning accuracy, but this incurs substantial compute. We introduce CoRefine: Confidence-Guided Self-Refine, a simple, efficient test-time method that matches or exceeds strong parallel approaches such as DeepConf@512 while using a tiny ~211k-parameter controller atop a frozen LLM. CoRefine consumes full-trace confidence and uses a small 3-layer Conv1D network to decide whether and how to refine the solution—or to halt—enabling targeted self-correction and confidence-regulated stopping. Across diverse reasoning benchmarks and open-source models, CoRefine attains parity or better accuracy with an average of ~2.7 refinement steps per problem, reducing computation by ≈190× relative to 512-sample baselines. Crucially, when the controller confidently halts, it achieves 92.6% precision—demonstrating that confidence patterns reliably signal correct answers without ground-truth verification. The method requires no backbone fine-tuning, integrates seamlessly with existing serving stacks, and complements verifier checks when available. By treating confidence as a control signal rather than a correctness guarantee, CoRefine provides a modular primitive for scalable reasoning and future agentic settings with imperfect verifiers.
Page and code: coming soon.