Chen Jin
Chen Jin
Home
Featured Research
Research Outputs
Blog
Contact
Light
Dark
Automatic
Diffusion Models
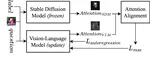
Diffusion Instruction Tuning
Created Lavender, an SFT method aligning VLM text-vision attention with Stable Diffusion, boosting Llama-3.2-11B and MiniCPM-v2.5 by up to 30% on 20 tasks.
Chen Jin
,
Ryutaro Tanno
,
Amrutha Saseendran
,
Tom Diethe
,
Philip Teare
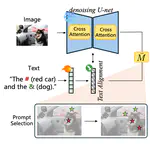
Segment Anyword
Training-free prompt learning for language-grounded segmentation using token-level cross-attention from a frozen diffusion model to generate object masks.
Zhihua Liu
,
Amrutha Saseendran
,
Lei Tong
,
Xilin He
,
Fariba Yousefi
,
Nikolay Burlutskiy
,
Dino Oglic
,
Tom Diethe
,
Philip Teare
,
Huiyu Zhou
,
Chen Jin
An Image is Worth Multiple Words: Discovering Object Level Concepts using Multi-Concept Prompt Learning
Personalised image generation extending textual inversion for mask-free learning of multiple concepts from a single sentence–image pair (Stable Diffusion).
Chen Jin
,
Ryutaro Tanno
,
Amrutha Saseendran
,
Tom Diethe
,
Philip Teare
Tackling Structural Hallucination in Image Translation with Local Diffusion
Training-free diffusion framework that reduces hallucinations via multiple local diffusion processes, cutting hallucinations by 40% (medical) and 25% (natural).
Seunghoi Kim
,
Chen Jin
,
Tom Diethe
,
Matteo Figini
,
Henry F. J. Tregidgo
,
Asher Mullokandov
,
Philip Teare
,
Daniel C. Alexander
Cite
×